
A common question in the #CogSciSci email group is what to do after students have done an assessment or a mock. Most commonly, people spend a lesson “going over” the paper, where the teacher goes through each question and students make corrections. There’s often some accompanying document for students (or teachers) to fill in tallying their errors in particular sections. Highlighting is normally involved. Personally, I don’t think this approach is hugely beneficial (for the time spent on it) and below I will explain why I think this and conclude with what I do.
Student psychology problems
The first thing to note is what is going through the students’ heads when you go over a test. Likelihood is, they aren’t really paying attention to the feedback, and are more focussed on the grade or score they got. In my experience this is because they are any of:
1) just plain upset and demotivated (“I can’t believe David did better than me”)
2) focussed on finding a way to scrounge another mark (but sir that’s exactly what I wrote!) or
3) so smug about their score that they don’t feel the need to pay attention.
This even changes question by question: if half the students got a question right, as soon as you start going through it unless they are the best students ever they just won’t be listening to you any more. As such, you will have a lesson where not all students are thinking throughout (1).
Sampling the domain
There is a more significant objection, which starts with a concept from assessment theory: sampling and inferences. Let’s look at this image, to represent all the things we want our students to know about a subject (the domain):
The black spots are “things you want students to know” and the lines between them are “connections.” So one black spot might represent “sodium has one electron in its outer shell” and a line might take it to a spot which states “when metals form ions they lose electrons from their outer shell.” If I ask a student “what happens when sodium becomes an ion?” I am testing those two black spots and the line between them.
We want to know how many of these spots and lines students have in their heads, but we simply cannot test whether or not a particular student has learnt everything in the domain: the tests would be too long (2). So instead, we pick some specific things from the domain and test those:

If a question asked: “what happens when sodium forms an ion?” we are testing two green spots and a connection between them, as above. The important bit comes next: the inference. If a student can adequately describe what happens when sodium forms an ion, I infer that if I had have asked them about say what happens when magnesium forms an ion, they would have got that right too. If that inference is justified, then it is valid. An invalid inference might be “this student knows what happens when transition metals form ions,” because the rules are different. The rule that governs sodium is the same one that governs magnesium, but the one that governs transition metals is different, so that inference would be invalid. The image below shows the things I tested in green, and the things I infer the student knows in orange:

So the purpose of the test is not to figure out just if a student knows the things on the test, it’s to figure out how much of the stuff that wasn’t on the test the student knows.
Assessment maestro Daniel Koretz puts it like this:
“most achievement tests are only small samples from much larger domains of achievement. For example, responses to the small sample of items on a mathematics test are used as a basis for inferences about mastery of the mathematics learned over one or many years of education.
In this way, a test is analogous to a political poll, in which the responses of a relatively small number of people are used to estimate the preferences of a far larger group of voters. In a poll, one samples individuals, while in a test, one samples behaviors from an individual’s larger repertoire, but the fundamental principal is the same: using the sample to estimate the larger set from which it is drawn. For this reason, scores are only meaningful to the extent that they justify an inference about the larger whole. That is, the validity of inferences depends on the extent to which performance on the tested sample generalizes to the much bigger, largely untested domain of achievement.”
This is also the key to understanding your mock. If a student got a particular question wrong, you don’t want to spend time in class going over that particular question. The whole point of that particular question is to give you an inference over something else – the extent to which the student understands the domain. Going over that question means you are going over the sample, when in reality you want to go over the domain. If 30 students get a question wrong, don’t go over that question. Go back to the domain that the question came from, and go over that.
There’s a simpler objection here too: it takes a long time to learn things. To my shame I only really realised this a couple of years ago, but without regular review and retrieval, things won’t get learned. So if students get something wrong in a test, going over that thing once in class is not a good call. Go back to the domain. Think about what their wrong answer tells you about the stuff that wasn’t in the test. Then do that. And do it again in a few lessons time. Add it into a retrieval roulette – whatever, just make sure you do it again.
Curriculum as a progression model
You may have heard people (including Ofsted) describe the curriculum as the progression model. The meaning of the phrase ties into what we were looking at earlier; as soon as your students start studying your domain, a long term outline might look like this:

Certainly, it’s probably not as neat as that, and the way you have planned to cover your domain might look a bit more like this:

The point is, your students are progressing through the domain. Whether or not they are “making progress” right now is to answer the question: how much of what I wanted them to learn this year have they learnt? As I’ve argued before, you cannot make any sensible decisions about pedagogy, teaching and learning or assessment until you have defined your domain and thought about what progress through it looks like. The test that you give your students measures progress in the sense that you infer from it the extent to which they have progressed through the domain.
GCSE grades are not a progression model
You will often see schools grading students from year 7 by GCSE grades, so they might be a 2 in year 7, 3 in year 8 etc, all on a flight path to get a 6 at GCSE. This is wrong, because grades are based on the entire domain: you get to the end of GCSE, this is what you are supposed to know. We find out how much of it you know as a percentage, compare you to other students and give you a grade. So in year 7-11 you aren’t progressing up the grades because the grades only work when applied to the entire domain. Using a GCSE grade on any one of the circles above is ridiculous, because the grade is a measure of the whole thing, not of one of the smaller circles.
Question level analysis (RAGging)
In Koretz’s passage above, we said that assessments are about inferring a student’s knowledge of the domain based on their performance in a sample of the domain. Whether or not you can “generalize” like this depends on other variables involved as well as student knowledge. The layout of the question, the amount of text, whether there is a supporting diagram, the stakes associated with the test, the time of day, whether or not the student slept or had breakfast or just got a message from their girlfriend or whatever. Those variables need to colour my inferences, and the fact that I don’t – and can’t – adequately assess their relative impact on the student means that I need to be very hesitant with my inferences. Triangulation with other data helps, longer tests helps, tests designed by someone who knows what they are doing helps, standardising the conditions helps and so on and so forth.
The effect of these other variables is what makes Question Level Analysis (where you look at the marks students got question by question) a highly dodgy enterprise. If students got a question on electrolysis wrong and one on rates right, that doesn’t mean you can infer they know rates and don’t know electrolysis. It could be that the question on electrolysis was just a harder question, or that the mark scheme was more benevolent, or that its layout on the paper was worse or it had more words in it or whatever. It might be that the question on electrolysis is incredibly similar to one they did in class, but the one on rates was completely new. You just can’t really know, so going crazy at the question level doesn’t strike me as sensible.
A further curve-ball is the “just right” phenomenon. It often happens in science (don’t know about other subjects) that a student manages to get marks on a particular question, but only just. They’ve said something which is awardable, but to the expert teacher it’s pretty obvious that their understanding is not as strong as another student who also got all the marks on that question. This further destabilises QLA as an enterprise. Still, you get some pretty coloured spreadsheets, and your assistant head for KS4 will be really impressed with how you are going to “target your interventions.” (3)
Grade descriptors are silly
A further ramification of all of the above is about grade descriptors and worrying about things like AO1, AO2 and AO3. Let’s look at an example first.
In the reaction between zinc and copper sulphate, energy is released to the surroundings and the temperature increases. If you stick them in a beaker together with a thermometer you can record that increase.
A common question would be to suggest an improvement to this experiment, with the answer being to put a lid on the beaker. If student A gets it right and student B gets it wrong, what inference can be made about their wider knowledge? Can I assume, as per grade descriptors, that student A is better at this:
“critically evaluate and refine methodologies, and judge the validity of scientific conclusions”
Obviously not. I can’t infer from their performance on this question that they would be better able to suggest an improvement to an experiment about rates, acids or electrolysis, because that’s just not how it works. Put graphically, if we look at the below, the area in the red circle represents the topic “acids” and the area in the blue represents the topic “energy”:
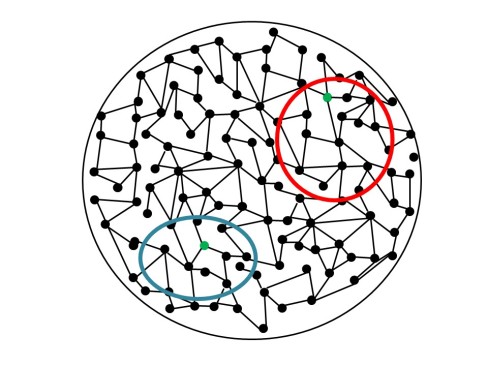 Each topic might contain a spot (given in green) which is about an experiment: an experiment about acids (red circle) and an experiment about energy (blue circle). But if we only test the red experiment, we can’t infer that they know the blue one, because they are in totally separate domains. Sure, they have in common that they are “questions about evaluating and refining methodologies” but they also have in common that they are “questions made up of letters and words” – just because they have one property in common doesn’t mean you can infer knowledge of one from the other.
Each topic might contain a spot (given in green) which is about an experiment: an experiment about acids (red circle) and an experiment about energy (blue circle). But if we only test the red experiment, we can’t infer that they know the blue one, because they are in totally separate domains. Sure, they have in common that they are “questions about evaluating and refining methodologies” but they also have in common that they are “questions made up of letters and words” – just because they have one property in common doesn’t mean you can infer knowledge of one from the other.
The same is true of stressing out over whether a question is AO1, 2 or 3. It may be the case that question 5 in the paper is AO2, but student A getting it right isn’t necessarily “good at applying knowledge” and student B getting it wrong isn’t necessarily “bad at applying their knowledge.” You can’t infer that, because you are essentially saying that if question 6 is also AO2, then student A is more likely to get it right than student B. That would be ridiculous, because it depends on the actual domain – the knowledge that is being tested – not other properties that questions 5 and 6 have in common. If question 5 is about acids and question 6 is about energy, then the students’ knowledge of energy is going to determine how well they can answer question 6, not their “ability to apply their knowledge of acids in unfamiliar contexts.”

What I do
As I’m marking student tests, I’ll look for glaring common errors. I address these on three levels:
1. This class, right now
Before I’ve given the papers back, I might spend a little time going over a couple of big issues. But I go back to the domain, so I don’t say “right there was a question about sodium bonding with chlorine that we got wrong so we’re going to do that again” I go right back to when I first taught students about bonding and say “there were some confusions about how electrons are transferred in ionic bonding so we are going to look at that again.” I teach a bit, give students some practice and then move on.
2. This class, in future
More importantly, I want to make sure this class have the opportunity in future to come back to this. So I might pencil in for next week to do a retrieval starter based on electron transfer, or build it in to a worksheet they are going to be doing next lesson.
3. Future classes
This is probably the most important level. I’m going to be teaching this content to three new classes next year. What am I going to do now to make sure that Future Adam spends a bit more time on this next year, so Future Adam’s students know this domain better this time next year? This is part of the reason why SLOP is powerful: I edit and change the booklets as soon as I’ve taught and assessed a unit, so I can make them bigger and better for the next group (as well as being used later as revision for this group).
Some do’s and don’ts
I realise I got a bit carried away on this post, so here’s a summary. Even if you to decide to do a don’t or don’t a do, I hope it’s a useful framework to think about assessments:
Don’t:
- Spend hours in class looking at the sample rather than the domain
- Go crazy looking at the marks students got for each individual question
- Give GCSE grades for individual assessments
- Use GCSE grades as a progression model
- Don’t infer anything about students’ general abilities like “evaluative thought”
- Go crazy over the AO of a question
Do:
- Think about what your students are thinking about (or not thinking about) when you are going over a test
- Go back to the domain
- Plan to revisit the domain
- Be sensible about what you are inferring about your student’s mastery of the domain
- Treat the curriculum as the progression model
There is a follow-up to this blog which looks at how you can actually implement these ideas here
(1) see here for more on that
(2) According to assessment boss Deep we’re miles away from even thinking about testing an entire domain. He recommends reading these
Kingston, N. M., Broaddus, A., & Lao, H. (2015). Some Thoughts on “Using Learning Progressions to Design Vertical Scales that Support Coherent Inferences about Student Growth.” Measurement: Interdisciplinary Research and Perspectives, 13(3–4), 195–199.
Rupp, A. A., Templin, J., & Henson, R. A. (2010). Diagnostic measurement: Theory, methods, and applications. New York, NY: Guilford Press
Not only would they be too long, but they would also probably not actually be particularly valid. It’s conceivable that a brilliant science student has mastered all the content, but in a different order and structure to how another brilliant science student did. A test which aimed to test each part of their cognitive structure might not account for individual idiosyncrasies in schema construction.
(3) see here for more on this

March 29, 2019 at 9:16 am
Reblogged this on Longsands LPD.
LikeLike
January 10, 2020 at 4:45 pm
Hi Adam,
Really interesting, thought-provoking post and I agree with most of what you’ve said, and am already reflecting on my own practice.
One question though – for the ‘This class, right now’ action, doesn’t that present the same problem as going through a question? Those that do know ionic bonding well could be left disengaged and not making much progress, couldn’t they?
Would a better method not be to provide 3-4 questions similar to those that the class struggled with as a whole as a means of differentiation? This way, those who need to recap ionic bonding with you can listen and benefit, and those that don’t can choose a different question to be getting on with to help them with an area in which they do need to improve.
One other suggestion I might add – providing walkthrough videos to go through the test (along with similar practice questions) rather than doing so in class means students can work at their own pace, and select which questions they most need to review and practice. This can be done in a computer room, on handheld devices, or as a homework.
More work for the teacher perhaps, but I find this method incredibly effective and the students often say how much they appreciate it too.
Thanks again for the ideas and debunking some myths for me!
LikeLike
July 7, 2020 at 8:18 am
I’ve always known that going through exams en masse is a waste of time but what you’ve written explains why, so thanks. So is going through them with individual students whilst the others ‘get on’ with something else.
I just wish the management would take this on board so I can use precious classroom time effectively. Still, next time they ask why I haven’t gone through the tests/exams/mocks I can just send the link to this.
What I’m going to do regarding ‘going through’ tests to please management has changed because of lockdown. A HW will be to watch me on Meet actually doing the test and talking about my thought processes. If they’re interested enough, then they’ll watch. If not, then at least class time is not wasted.
LikeLike
June 8, 2022 at 12:04 pm
yes agree with this entirely. however we must find a way of showing student progression and a way of informing them which grade they are heading for. That’s only fair on them and their parents…remember when sats level 5 in year 8 corresponded to getting a grade c in their gcse? That was useful…
LikeLike